Re-discovering the Higgs boson in the Cloud
It’s hard to believe that it has already been more than seven years since the discovery of the Higgs boson. Since then, numerous papers have been published by the ATLAS and CMS collaborations measuring the long-awaited particle’s properties in detail. Have you ever wondered whether one could repeat one of the analyses that led to the discovery? The CMS software (CMSSW) release and the corresponding analysis code that were used at that time are based on the Scientific Linux CERN 6 distribution, whose latest release dates back to April 2017. There are only a few publicly accessible machines left that still run this Linux version, and soon none will be available anymore. Does this mean that this groundbreaking achievement will not be reproducible?
Fortunately, the answer is “no”. There are still ways to re-run the Higgs boson analyses, and even better, these methods are faster and more robust than the original analyses ever were. This was demonstrated last spring at a conference called KubeCon + CloudNativeCon Europe 2019, and more recently during the CHEP 2019 conference, thanks to a collaborative effort between ATLAS and CMS experiments and our colleagues from CERN’s IT department. But let's take a moment to discuss the steps that led to this result
The key to making this possible are so-called software containers. These containers can include anything from a simple web server to a software framework that runs e.g. a machine learning training job. In the case of a physics analysis, such as the Higgs search mentioned above, they contain the needed Linux distribution, the CMSSW release, an extract of the database including the data-taking conditions, as well as the compiled analysis code. A big advantage of software containers in general is that they largely isolate the software from the host system, making their execution not only safer, but also allowing for more uniform operation. All required software, libraries and configuration files are bundled in the container so that they can easily be copied and executed on other platforms. In addition, this enables full reproducibility, as for instance desired by the data preservation efforts of the LHC experiments. The only “input” needed for the execution are the actual data sets.
While most analysts in high energy physics (HEP) do not yet use containers in their daily work, they are becoming more and more common. The CMS collaboration has been using a dedicated set of software containers since a while for the data set production system, and if you are a member of the ATLAS collaboration, you can even submit jobs to the Worldwide LHC Computing Grid to be executed using your own software containers. The HTCondor-based batch system at CERN also supports the execution of containers (see their documentation).
Furthermore, when it comes to machine learning, the software stack is often much more recent than what is available on LXPLUS. There are clear advantages if you can build a container on your computer or using CERN’s GitLab installation (see example), and then work in the same environment on any machine. This also facilitates executing the containers in remote data centres, which is often referred to as cloud computing.
Over the last couple of years, containers have become the de-facto standard way of operating in the tech industry. This is largely due to a software called Docker, a set of tools initially released in 2013, which significantly simplified the creation and execution of containers on Linux servers. About a year later, a container-orchestration system called Kubernetes was announced. This platform automates the deployment, scaling, and management of containers, and has widely been adopted in industry.
Recent innovations in these areas are discussed at the KubeCon + CloudNative conference that focuses on the use of Kubernetes and the future of “cloud native computing”. KubeCon + CloudNativeCon is one of the largest open source software conferences in the world. The 2019 edition in Europe had about 7,700 participants, and more than 12,000 attended the most recent version that was held in North America.

The CERN group at Kubecon Europe 2019, celebrating the 5th birthday of Kubernetes (left to right): Clemens Lange, Thomas Hartland, Lukas Heinrich, Belmiro Moreira, Ricardo Rocha, Antonio Nappi, and Spyridon Trigazis.
With container-related tools available, the question that remains is whether they can realistically be used in a physics analysis. For KubeCon Europe 2019 that took place in May 2019 in Barcelona, Spain, I had joined forces with a few colleagues from CERN (Ricardo Rocha, Thomas Hartland, both IT Department, and Lukas Heinrich, EP Department) to demonstrate that by orchestrating software containers and using the practically unlimited computing resources available in public clouds, a physics analysis that would typically require several hours to days can be performed within minutes.
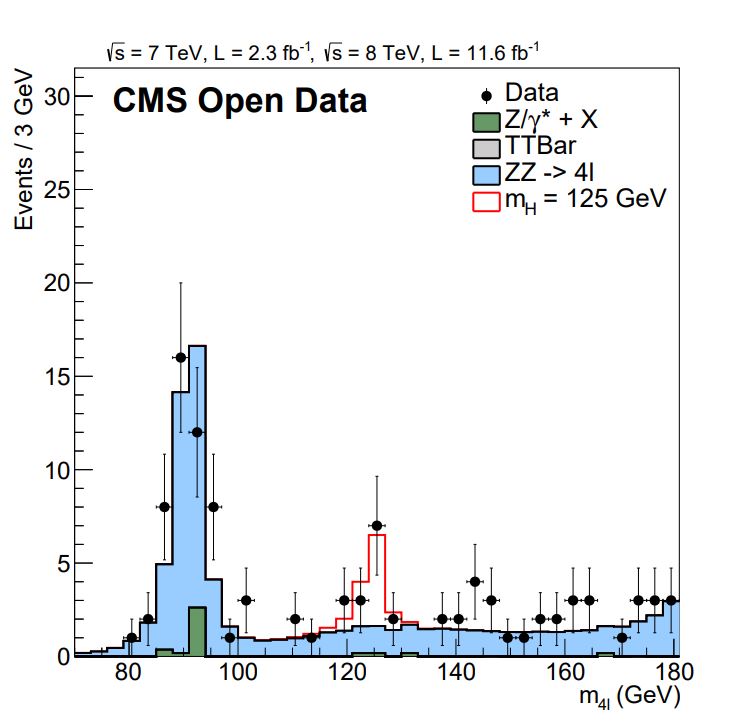 In order to be able to engage with the predominantly tech crowd at this conference, we had to come up with something special. Not everyone might be interested in a HEP analysis, but the Higgs boson has so far intrigued almost everyone. What better to do than show everyone the Higgs boson mass peak emerge from the data? Luckily, the CMS Open Data project makes this possible! Although the actual analysis code used for the Higgs analyses is not publicly available, the CMS Open Data team provides several analysis examples. One of them is a simplified analysis of the Higgs boson decaying to four leptons via two Z bosons.
In order to be able to engage with the predominantly tech crowd at this conference, we had to come up with something special. Not everyone might be interested in a HEP analysis, but the Higgs boson has so far intrigued almost everyone. What better to do than show everyone the Higgs boson mass peak emerge from the data? Luckily, the CMS Open Data project makes this possible! Although the actual analysis code used for the Higgs analyses is not publicly available, the CMS Open Data team provides several analysis examples. One of them is a simplified analysis of the Higgs boson decaying to four leptons via two Z bosons.
The reconstruction of this final state is relatively easy—it’s just adding up the four-vectors of the four identified final state leptons to yield the Higgs boson mass. However, the challenge is processing the huge amounts of data: about 70 Terabytes of data spread across 25,000 files, which correspond to 50% of the 2011 and 2012 data sets plus the corresponding simulation samples that were openly available at that time. Thanks to a collaboration with Google through the CERN Openlab, we were given credits so that we could scale to 25,000 CPU cores, allowing us to process one file per core, 25,000 jobs running in parallel.
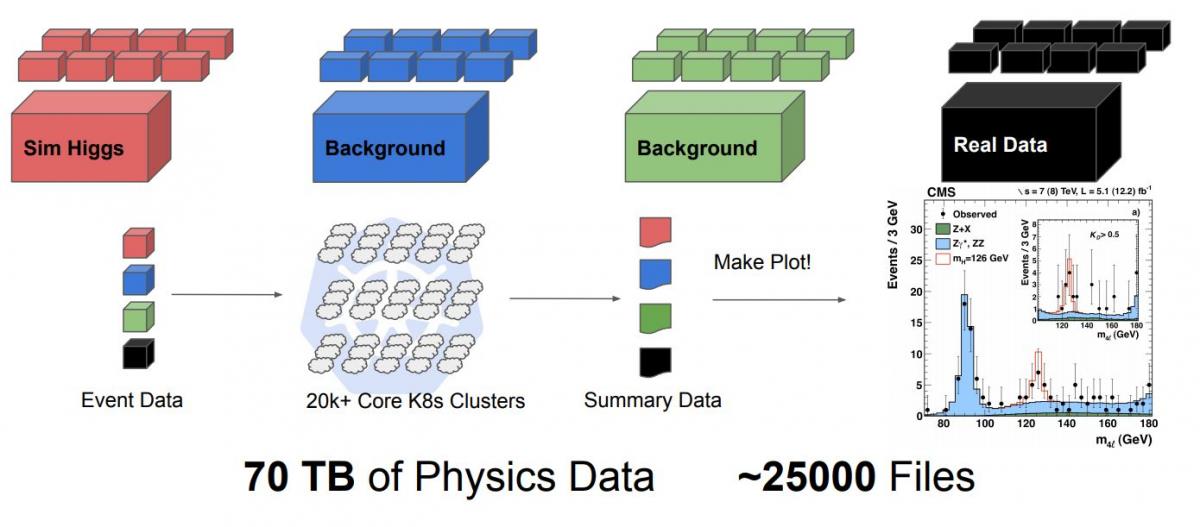
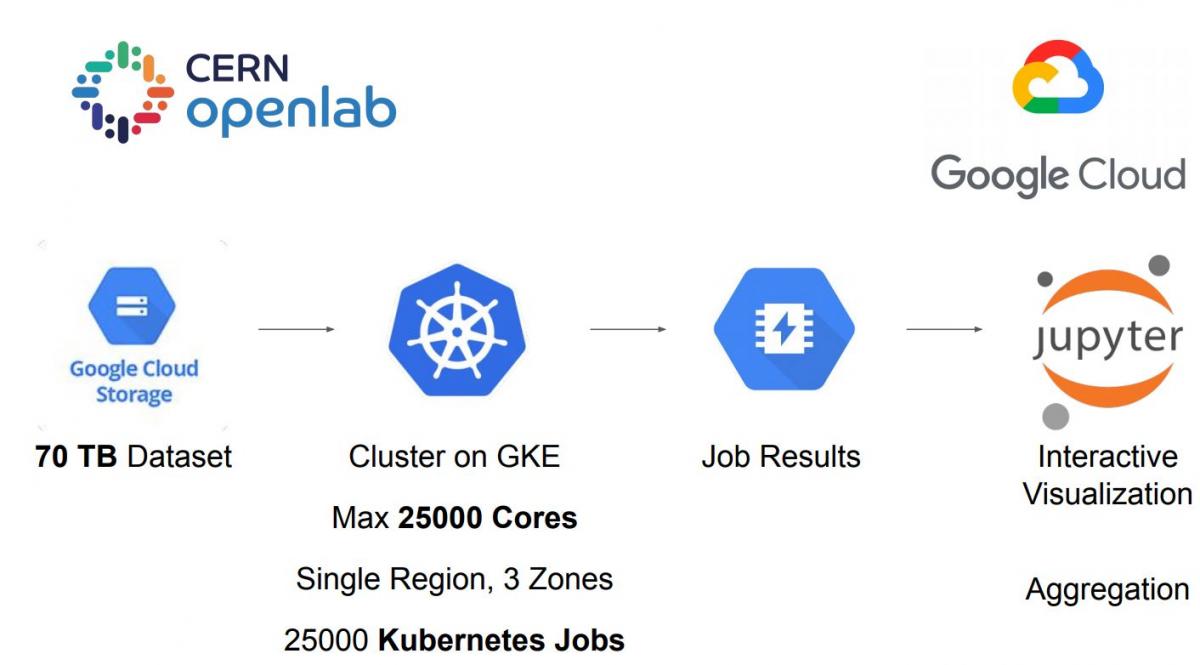
The figures show how the rediscovery of the H ➜ ZZ ➜ 4 leptons channel would look like in a cloud native approach (top) and how the use of standard tools facilitates the transition from traditional HEP infrastructure to the cloud (taken from Lukas Heinrich's and Ricardo Rocha's presentation during CHEP 2019).
Another advantage of cloud computing is that you only pay for what you use: it turns out that with only around 1,000 CHF of cloud computing fees one can repeat our demonstration (i.e. process all relevant simulation and collision data sets from 2011 and 2012 in the cloud). This could for instance be used to write out the data into a lighter format, containing only the information required for further analysis and thus allowing to use public cloud services for performing an analysis.
Following the original ideas and after developing some tools, we were invited to give a keynote presentation, representing CERN in front of a huge audience. We were very much relieved that the demonstration worked! The Higgs boson mass peak showed up within a few minutes after starting the jobs and the audience cheered! You can watch the video recording on YouTube. It was a great experience being part of such an endeavour. Also, everyone we talked to was excited to learn about CERN and our work.
As an experimental physicist at CERN, could you do the same? In principle, yes! There were a couple of tricks that we had to play to be able to process the data as quickly as possible, such as copying the files to faster hard disks and streaming the results into an in-memory database instead of storing them on disk, but this is only really an issue when processing Terabytes of data in seconds. In your daily work, you are usually able to run several hundred jobs in parallel using the batch system or the grid. If you put your analysis code into a container, and e.g. store that container in CERN’s GitLab container registry, you will furthermore have a self-contained backup of your analysis that is guaranteed to run for many years. Your analysis will be fully reproducible, and reusing it e.g. for a re-interpretation in the future will be straight-forward. Building the containers for your analysis code is actually easier when working in a HEP environment, since you can mount the experimental software such as CMSSW via the CernVM file system (CVMFS) that is available on LXPLUS/LXBATCH and most grid sites. Only when using the public cloud, the full CMSSW release needs to be added into the software container.
There are further implications in using this containerisation approach that strongly align with the principles of Open Science. Once the data are publicly accessible, anyone can repeat and reuse the analysis. The big step forward here is that one does not need the grid or a batch farm such as the ones available only to HEP experimentalists, but can orchestrate the software containers using Kubernetes on a public cloud service. Anyone could rediscover the Higgs boson!